How to read: Character level deep learning
UPDATE 30/03/2017: The repository code has been updated to tf 1.0 and keras 2.0! The repository will not be maintained any more.
2016, the year of the chat bots. Chat bots seem to be extremely popular these days, every other tech company is announcing some form of intelligent language interface. The truth is that language is everywhere, it’s the way we communicate and the way we manage our thoughts. Most, if not all, of our culture & knowledge is encoded and stored in some language. One can think that if we manage to tap to that source of information efficiently then we are a step closer to create ground breaking knowledge systems. Of course, chat-bots are not even close to “solving” the language problem, after all language is as broad as our thoughts. On the other hand researchers still make useful NLP application that are impressive, like gmail’s auto-reply or deep-text from Facebook.
After reading a few papers about NLP, and specifically deep learning applications, I decided to go ahead and try out a few things on my own. In this post I will demonstrate a character level models for sentiment classification. The models are built with my favourite framework Keras (with Tensorflow as back-end). In case you haven’t used Keras before I strongly suggest it, it is simple and allows for very fast prototyping (thanks François Chollet. After version 1.0 and the introduction of the new functional API, creating complex models can be as easy as a few lines. I’m hoping to demonstrate some of it’s potential as we go along.
If you want to get familiar with the framework I would suggest following these links:
- 30 seconds to Keras
- Keras examples
- Building powerful image classification models using very little data
I also assume that most people reading this have some basic knowledge about convolution networks, mlps, and rnn/lstm models.
A very popular post from Andrej Karpathy talking about the effectiveness of recurrent nets presents a character level language model built with RNNs, find it here. A simple implementation of this model for Keras, here.
Karpathy’s blog post was probably my first encounter with character level modelling and I have to say I was fascinated by it’s performance. In English character level might not be as appealing as other languages like Greek(my native language). Trying to build vocabularies in Greek can be a bit tricky since words change given the context, so working on character level and letting your model figure out the different word permutations is a very appealing property.
If you have a question about a model, the best thing to do with it is experiment. So let’s do it!
What is a character level model?
Let’s assume the typical problem of sentiment analysis, given a text, for a example a movie review we need to figure out if the review is positive(1) or negative(0). Let’s denote the text input, which is a sequence of words, and the corresponding sentiment, so we create a network that will predict the label of the sample. In such settings a typical approach is to split the text into a sequence of words, and then learn some fixed length embedding of the sequence that will be used to classify it.

In a recurrent model like the above, each word is encoded as a vector (a very nice explanation of word embeddings can be found in Christopher Olah blog post - along with an explanatory post for LSTMs - highly recommended reads)
Like any typical model that uses a word as it’s smallest input entity, a character level model will use the character as the the smallest entity. E.g: 
This model is reading characters one by one, to create an embedding of the of a given sentence/text. As such our neural network will try to learn that specific sequences of letters form words separated by spaces or other punctuation points. A paper from A. Karpathy & J. Johnson, “Visualizing and Understanding Recurrent Networks”, demonstrates visually some of the internal processes of char-rnn models.
In their paper “Exploring the Limits of Language Modeling”, the Google Brain team show that a character level language model can significantly outperform state of the art models. Their best performing model combines an LSTM with CNN input over the characters, the figure bellow is taken from their paper: 
In “Text Understanding from Scratch” Zhang et. al. uses pure character level convolution networks to perform text classification with impressive performance. The following figure taken from the paper describes the model: 
Building a sentiment model
Let’s try build our model on the popular IMDB review database, the labelled data can be found on this Kaggle competition webpage, we are just going to use the labelled labeledTrainData.tsv which contains 25000 reviews with labels. If you haven’t worked text before, the competition website offers a nice 4-part tutorial to create sentiment prediction models.
Our goal is to encode text from character level, so we’ll begin by splitting the text into sentences. Creating sentences from reviews bounds the maximum length of a sequence so it can be easier for our model to handle. After encoding each sentence from characters to a fixed length encoding we use a bi-directional LSTM to read sentence by sentence and create a complete document encoding.
The following figure elaborates the full model architecture
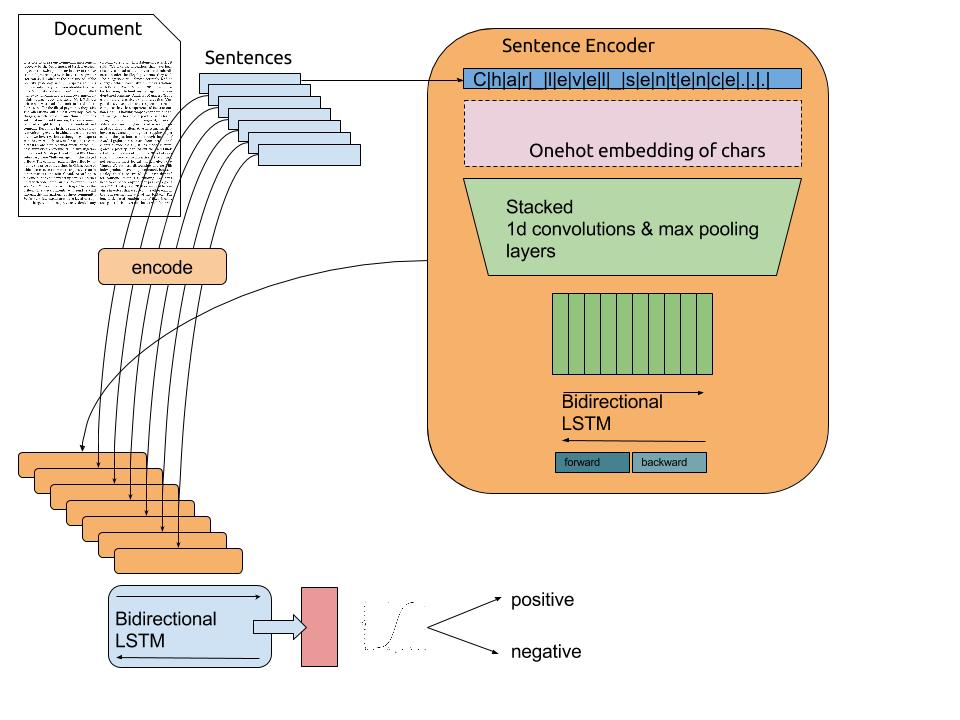
This model starts from reading characters and forming concepts of “words”, then uses a bi-directional LSTM to read “words” as a sequence and account for their position. After that each sentence encoding is being passed through a second bi-directional LSTM that does the final document encoding.
Preprocessing
There is minimum preprocessing required for this approach, since our goal is to provide simple text and let the model figure out what that means. So we follow 3 basic steps:
- Remove html tags
- Remove non characters (e.g. weird symbols)
- Split into sentences
data = pd.read_csv("labeledTrainData.tsv", header=0, delimiter="\t", quoting=3)
txt = ''
docs = []
sentences = []
sentiments = []
for cont, sentiment in zip(data.review, data.sentiment):
sentences = re.split(r'(?<!\w\.\w.)(?<![A-Z][a-z]\.)(?<=\.|\?)\s', clean(striphtml(cont)))
sentences = [sent.lower() for sent in sentences]
docs.append(sentences)
sentiments.append(sentiment)The next step is to create a our character set.
for doc in docs:
for s in doc:
txt += s
chars = set(txt)
print('total chars:', len(chars))
char_indices = dict((c, i) for i, c in enumerate(chars))
indices_char = dict((i, c) for i, c in enumerate(chars))Create training examples and targets. We bound the maximum length of the sentence to be 512 chars while the maximum number of sentences in a document is bounded at 15. We reverse the order of characters putting the first character at the end of the 512D vector.
maxlen = 512
max_sentences = 15
X = np.ones((len(docs), max_sentences, maxlen), dtype=np.int64) * -1
y = np.array(sentiments)
for i, doc in enumerate(docs):
for j, sentence in enumerate(doc):
if j < max_sentences:
for t, char in enumerate(sentence[-maxlen:]):
X[i, j, (maxlen-1-t)] = char_indices[char]Sentence Encoder
We now have our training examples X and the corresponding y target sentiments. X is indexed as (document, sentence, char). The first part of our model is to build a sentence encoder from characters. Using Keras we can do that in a few lines of code.
We need to declare a lambda layer that will create a onehot encoding of a sequence of characters on the fly. Holding one-hot encodings in memory is very inefficient.
def binarize(x, sz=71):
return tf.to_float(tf.one_hot(x, sz, on_value=1, off_value=0, axis=-1))
filter_length = [5, 3, 3]
nb_filter = [196, 196, 256]
pool_length = 2
in_sentence = Input(shape=(maxlen,), dtype='int64')
# binarize function creates a onehot encoding of each character index
embedded = Lambda(binarize, output_shape=binarize_outshape)(in_sentence)
for i in range(len(nb_filter)):
embedded = Convolution1D(nb_filter=nb_filter[i],
filter_length=filter_length[i],
border_mode='valid',
activation='relu',
init='glorot_normal',
subsample_length=1)(embedded)
embedded = Dropout(0.1)(embedded)
embedded = MaxPooling1D(pool_length=pool_length)(embedded)
forward_sent = LSTM(128, return_sequences=False, dropout_W=0.2, dropout_U=0.2, consume_less='gpu')(embedded)
backward_sent = LSTM(128, return_sequences=False, dropout_W=0.2, dropout_U=0.2, consume_less='gpu', go_backwards=True)(embedded)
sent_encode = merge([forward_sent, backward_sent], mode='concat', concat_axis=-1)
sent_encode = Dropout(0.3)(sent_encode)
encoder = Model(input=in_sentence, output=sent_encode)The functional api of Keras allows us to create funky structures with minimum effort. This structure has 3 1DConvolution layers, with relu nonlinearity, 1DMaxPooling and dropout. On top of that there is a bidrectional LSTM (just 2 lines of code).
forward_sent = LSTM(128, return_sequences=False, dropout_W=0.2, dropout_U=0.2, consume_less='gpu')(embedded)
backward_sent = LSTM(128, return_sequences=False, dropout_W=0.2, dropout_U=0.2, consume_less='gpu', go_backwards=True)(embedded)CNN Sentence Encoder
An alternative sentence encoder is one that only uses convolutions and fully connected layers to encode a sentence. The following code composes a network with 2 streams of 3 convolutional layers that operate on different convolutional lengths, after that a temporal max pooling is performed and the 2 streams are concatenated to create a merged vector. The idea behind temporal maxpooling is to identify those features that give a strong sentiment, that could correspond to words like bad, excellent, dislike etc. A temporal max pooling hypothetically will strongly activate some neurons in the sequence, but we do not care about the position of these ‘words’, we are only looking for high responses of certain patterns.
The following code creates the 2 stream cnn network:
def max_1d(X):
return K.max(X, axis=1)
def char_block(in_layer, nb_filter=[64, 100], filter_length=[3, 3], subsample=[2, 1], pool_length=[2, 2]):
block = in_layer
for i in range(len(nb_filter)):
block = Convolution1D(nb_filter=nb_filter[i],
filter_length=filter_length[i],
border_mode='valid',
activation='relu',
subsample_length=subsample[i])(block)
# block = BatchNormalization()(block)
block = Dropout(0.1)(block)
if pool_length[i]:
block = MaxPooling1D(pool_length=pool_length[i])(block)
block = Lambda(max_1d, output_shape=(nb_filter[-1],))(block)
block = Dense(128, activation='relu')(block)
return block
in_sentence = Input(shape=(maxlen, ), dtype='int64')
embedded = Lambda(binarize, output_shape=binarize_outshape)(in_sentence)
block2 = char_block(embedded, [100, 200, 200], filter_length=[5, 3, 3], subsample=[1, 1, 1], pool_length=[2, 2, 2])
block3 = char_block(embedded, [200, 300, 300], filter_length=[7, 3, 3], subsample=[1, 1, 1], pool_length=[2, 2, 2])
sent_encode = merge([block2, block3], mode='concat', concat_axis=-1)
sent_encode = Dropout(0.4)(sent_encode)
encoder = Model(input=in_sentence, output=sent_encode)Document Encoder
The sentence encoder feeds it’s output to a document encoder that is composed of a bidirectional lstm with fully connected layers at the top.
sequence = Input(shape=(max_sentences, maxlen), dtype='int64')
encoded = TimeDistributed(encoder)(sequence)
forwards = LSTM(80, return_sequences=False, dropout_W=0.2, dropout_U=0.2, consume_less='gpu')(encoded)
backwards = LSTM(80, return_sequences=False, dropout_W=0.2, dropout_U=0.2, consume_less='gpu', go_backwards=True)(encoded)
merged = merge([forwards, backwards], mode='concat', concat_axis=-1)
output = Dropout(0.3)(merged)
output = Dense(128, activation='relu')(output)
output = Dropout(0.3)(output)
output = Dense(1, activation='sigmoid')(output)
model = Model(input=sequence, output=output)The TimeDistributed layer is what allows the model to run a copy of the encoder to every sentence in the document. The final output is a sigmoid function that predicts 1 for positive, 0 for negative sentiment.
The model is trained with an cnn/bi-lstm encoder on 20000 reviews and validating on 2500 reviews. The optimzer used is adam with the default parameters. The model roughly achieves ~86% accuarcy on the validation in the first 15 epochs. (Note: A sligthly different architecture with a two stream cnn sentence net performs similarly)

After the 15 epochs the model’s improvement on the validation set is stalling but still increases performance on the training set. A better tuned model would probably overcome this but the purpose of this post is to demonstrate how create character level models and not achieve the best possible result. Some things that might improve the generalisation and reduce overfitting:
-
Different hidden layer sizes, smaller layers will reduce the abillity of the model to overfit to the training set.
-
Larger dropout rates.
-
l2/l1 regularization.
-
A deeper and/or wider architecture of cnn encoder.
-
Different doc encoder, maybe include an attention module?
All of the code can be found in my github repository: https://github.com/offbit/char-models
Final words
I really enjoy the idea of creating character level models, there is something appealing in creating models that work on such level. Character level modelling enables us to deal with common miss-spellings, different permutation of words (think run, runs, running) that are even more common in some other languages. I’m also expecting to work better in text that contains, emojis, signaling chars, hashtags and all the funky annotations that are being used in social media. In the best of my knowledge I haven’t seen results of char-level models in twitter data for example, but I’m guessing twitter/fb/google already test these things in large social media uncurated corpus. Some of the aforementioned papers already show promising results, and given enough data character level models shine.
If you liked my post drop me a line at twitter @techabilly, or email: s.vafeias_at_gmail .